I’m assuming that most readers are familiar with what RAID, the “Redundant Array of Inexpensive Disks”, is. Using RAID for disk redundancy has been around for a long time, apparently first mentioned in 1987 at the University of California, Berkeley (see also: The Story So Far: The History of RAID). I’m honestly not sure why they chose the term “inexpensive” back in 1987 (I suppose “RAD” isn’t as catchy of a name), but regardless of the wording, a RAID is a fairly easy way to protect yourself against hard drive failure. Presumably, any production server will have a RAID these days, especially with hard drives being as inexpensive as they are today (unless you purchase them list price from major hardware vendors, that is). Another reason why RAID is popular, is of course the fact that hard drives are probably the most common component to break in a computer. You can’t really blame them either, they do have to spin an awful lot.

Lesson #1: Don’t neglect your backups because you are using RAID arrays
That being said, we recently had an unpleasant and unexpected issue in our office with a self-built server. While it is a production server, it is not a very critical one, and as such a down-time of 1-2 days with a machine like that is acceptable (albeit not necessarily desired). Unlike the majority of our “brand-name” servers, which are under active support contracts, this machine was using standard PC components (it’s one of our older machines), including an onboard RAID that we utilized for both the OS drive as well as the data drive (it has four disks, both in a RAID 1 mirror). Naturally, the machine is monitored through EventSentry.
Well, one gray night it happened – one of the hard drives failed and a bunch of events (see myeventlog.com for an example) were logged to the event log, and immediately emailed to us. After disappointingly reviewing the emails, the anticipated procedure was straightforward:
1) Obtain replacement hard drive
2) Shut down server
3) Replace failed hard drive
4) Boot server
5) Watch RAID rebuilding while sipping caffeinated beverage
The first 2 steps went smoothly, but that’s unfortunately how far our IT team got. The first challenge was to identify the failed hard drive. Since they weren’t in a hot-swappable enclosure, and the events didn’t indicate which drive had failed, we chose to go the safe route and test each one of them with the vendors supplied hard drive test utility. I say safe, because it’s possible that a failed hard drive might work again for a short period of time after a reboot, so without testing the drives you could potentially hook the wrong drive up. So, it’s usually a good idea to spend a little bit of extra time in that case, to determine which one the culprit is.
Eventually, the failed hard drive was identified, replaced with the new (exact and identical) drive, connected, and booted again. Now normally, when connecting an empty hard drive, the raid controller initiates a rebuild, and all is well. In this case however, the built-in NVidia RAID controller would not recognize the RAID array anymore. Instead, it congratulates us on having installed two new disks. Ugh. Apparently, the RAID was no more – it was gone – pretty much any IT guys nightmare.
No matter what we tried, including different combinations, re-creating the original setup with the failed disks, trying the mirrored drive by itself, the RAID was simply a goner. I can’t retell all the things that were tried, but we ultimately had to re-create the RAID (resulting in an empty drive), and restore from backup.
We never did find out why the RAID 1 mirror that was originally setup was not recognized anymore, and we suspect that a bug in the controller firmware caused the RAID configuration to be lost. But regardless of what was ultimately the cause, it shows that even entire RAID arrays may fail. Don’t relax your backup policy just because you have a RAID configured on a server.
Lesson #2: Use highly reliable RAID levels, or configure a hot spare
Now I’ll admit, the majority of you are running your production servers on brand-name machines, probably with a RAID1 or RAID5, presumably under maintenance contracts that ship replacement drives within 24 hours or less. And while that does sound good and give you comfort, it might actually not be enough for critical machines.
Once a drive in a RAID5 or RAID1 fails, the RAID array is in a degraded state and you’re starting to walk on very thin ice. At this point, of course, any further disk failure will require a restore from backup. And that’s usually not something you want.
So how could a RAID 5 not be sufficiently safe? Please, please: Let me explain.
Remember that the RAID array won’t be fully fault tolerant until the RAID array is rebuilt – which might be many hours AFTER you plug in the repaired disk depending on the size, speed and so forth. And it is during the rebuild period that the functional disks will have to work harder than usual, since the parity or mirror will have to be re-created from scratch, based on the existing data.
Is a subsequent disk failure really likely though? It’s already pretty unlikely a disk fails in the first place – I mean disks don’t usually fail every other week. It is however much more likely than you’d think, somewhat depending on whether the disks are related to each other. What I mean with related, is whether they come from the same batch. If there was a problem in the production process – resulting in a faulty batch – then it’s actually quite likely that another bites the dust sooner rather than later. It happened to a lot of people – trust me.
But even if the disks are not related, they probably still have the same age and wear and, as such, are likely to fail in a similar time frame. And, like mentioned before, the RAID array rebuild process will put a lot of strain on the existing disks. If any disk is already on its last leg, then a failure will be that much more likely during the RAID array rebuild process.
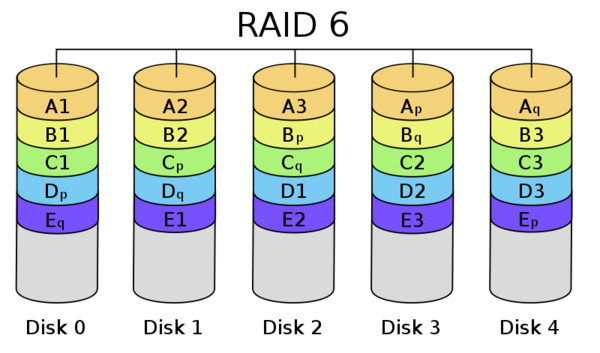 RAID 6, if supported by your controller, is usually preferable to a RAID5, as it includes two parity blocks, allowing up to two drives to fail. RAID 10 is also a better option with potentially better performances, as it too continues to operate even when two disks fail (as long as it’s not the disks that are mirrored). You can also add a hot spare disk, which is a stand-by disk that will replace the failed disk immediately.
RAID 6, if supported by your controller, is usually preferable to a RAID5, as it includes two parity blocks, allowing up to two drives to fail. RAID 10 is also a better option with potentially better performances, as it too continues to operate even when two disks fail (as long as it’s not the disks that are mirrored). You can also add a hot spare disk, which is a stand-by disk that will replace the failed disk immediately.
If you’re not 100% familiar with the difference between RAID 0, 1, 5, 6, 10 etc. then you should check out this Wikipedia article: It outlines all RAID levels pretty well.
Of course, a RAID level that provides higher availability is usually less efficient in regards to storage. As such, a common counterargument against using a more reliable RAID level is the additional cost associated with it. But when designing your next RAID, ask yourself whether the savings of an additional hard drive is worth the additional risk, and the potential of having to restore from a backup. I’m pretty sure that in most cases, it’s not.
Lesson #3: Ensure you receive notifications when a RAID array is degraded
Being in the monitoring business, I need to bring up another extremely
important point: Do you know when a drive has failed? It doesn’t help much to have a RAID when you don’t know when one or more drives have failed.
Most server
management software can notify you via email, SNMP and such – assuming
it’s configured. Since critical events like this almost always trigger
event log alerts as well though, a monitoring solution like EventSentry can simplify the notification process.
Since EventSentry monitors event logs, syslog as well as SNMP traps, you can take a uniform approach to notifications. EventSentry can notify you of RAID failures regardless of the hardware vendor you
use – you just need to make sure the controller logs the error to the
event log.
Lesson #4+5: Test Backups, and store backups off-site
Of course one can’t discuss reliability and backups without preaching the usual. Test your backups, and store (at least the most critical ones) off-site.
Yes, testing backups is a pain, and quite often it’s difficult as well and requires a substantial time commitment. Is testing backups overkill, something only pessimistic paranoids do? I’m not sure. But we learned our lessen the hard way when all of our 2008 backups were essentially incomplete, due to a missing command-line switch that recorded (or in our case did not) the system state. We discovered this after, well, we could NOT restore a server from a backup. Trust me: Having to restore a failed server and having only an incomplete, out-of-date or broken backup, is not a situation you want to find yourself in.
My last recommendation is off-site storage. Yes, you have a sprinkler system, building security and feel comfortably safe. But look at the picture on top. Are you prepared for that? If not, then you should probably look into off-site backups.
So, let me recap:
1. Don’t neglect your backups because you are using RAID arrays.
2. Use highly reliable RAID levels, or configure a hot spare.
3. Ensure you receive notifications when a RAID array is degraded
4. Test your backups regularly, but at the very least test them once to ensure they work.
5. Store your backups, or at least the most critical, off-site.
Stay redundant,
Ingmar.