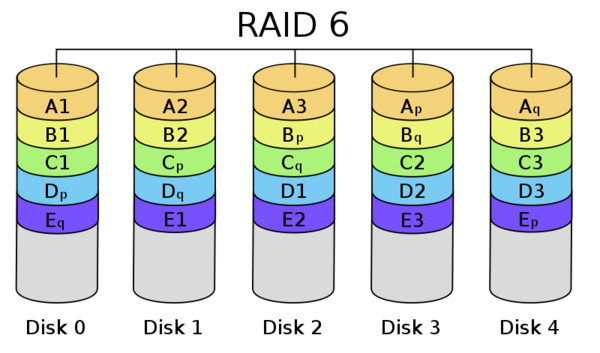
Windows Server has long provided admins the ability to create a software RAID, enabling redundant disks without a (potentially expensive) hardware RAID controller. If you are already using Windows Server 2008’s software RAID capabilities, and think that Windows will somehow notify you when a disk in an array fails, then you can skip to “Just say something!” below.
Background
Creating a RAID can all be done from Disk Management view in the Computer Management console, without any scripting or command-line tools.
Software RAIDs are not as powerful and fast as their hardware counterparts, but are nevertheless a good way to enable disk redundancy. Software RAIDs make sense in a variety of scenarios:
• When you are on a budget and don’t want to spend a few hundred $$ on a hardware RAID controller
• When you need to enable redundancy on a server that wasn’t originally designed with redundancy in mind (as if that would ever happen!)
• When you need to add redundancy to a server without reinstalling the OS or restoring from backup
Windows Server lets you do all this, and it’s included with the OS – so why not take advantage of it? The last point is often overlooked I think – you can literally just add a hard disk to any non-redundant Windows server and create a mirror – with less than dozen clicks!
Since this article is starting to sound like a software raid promotion, and for the sake of completeness, I am listing SOME of the advantages of a hardware RAID here as well:
• Faster performance due to dedicated hardware, including cache
• More RAID levels than most software RAIDs
• Hot-plug replacement of failed disks
• Ability to select a hot spare disk
• Better monitoring capabilities (though this article will alleviate this somewhat)
But despite being far from perfect, software RAIDs do have their time and place.
Just Say Something Please!
Unfortunately, despite all the positive things about software RAID, there is a major pitfall on Windows 2008: The OS will not tell you when the RAID has failed. If the RAID is in a degraded state (usually because a hard disk is dead) then you will not know unless you navigate to the Disk Management view. The event logs are quiet, there are no notifications (e.g. tray), and even WMI is silent as a grave. Nothing. Nada. Nix.
What’s peculiar is that this is a step back from Windows 2003, where RAID problems were actually logged to the System event log with the dmboot and dmio event sources. What gives?
Even though a discussion on why that is (or is not) seems justified, I will focus on the solution instead.
The Solution
Fortunately, there is a way to be notified when a RAID is “broken”, thanks in part to the diskpart.exe tool (which is part of Windows) and EventSentry. With a few small steps we’ll be able to log an event to the event log when a drive in a software RAID fails, and send an alert via email or other notification methods.
Diskpart is pretty much the command-line interface to the Disk Management MMC snap-in, which allows you to everything the MMC snap-in does – and much more! One of the things you can do with the tool is to review the status of all (logical) drives. Since we’re interested as to whether a particular RAID-enabled logical drive is “Healthy”, we’ll be looking at logical drives.
So how can we turn diskpart’s output into an email (or other) alert? Simple: We use EventSentry‘s application scheduler to run diskpart.exe on a regular basis (and since the tool doesn’t stress the system it can be run as often as every minute) and generate an alert. The sequence looks like this:
• EventSentry runs our VBScript (which in turn runs diskpart) and captures the output
• When a problem is detected, EventSentry logs an error event 10200 to the application event log, including output from step 1.
• An event log filter looks for a 10200 error event, possibly looking at the event message as well (for custom routing).
Diskpart
Diskpart’s output is pretty straightforward. If you just run diskpart and execute the “list volume” command, you will see output similar to this:
Volume ### Ltr Label Fs Type Size Status Info
---------- --- ----------- ----- ---------- ------- --------- --------
Volume 0 System Rese NTFS Simple 100 MB Healthy System
Volume 1 C NTFS Mirror 141 GB Healthy Boot
Volume 2 D System Rese NTFS Simple 100 MB Healthy
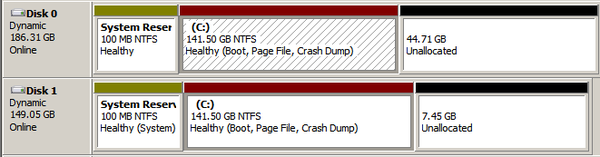
Notice the “Status” column, which indicates that our “BOOT” volume is feeling dandy right now. However, when a disk fails, the status is updated and reads “Failed Rd” instead:
Volume ### Ltr Label Fs Type Size Status Info
---------- --- ----------- ----- ---------- ------- --------- --------
Volume 0 System Rese NTFS Simple 100 MB Healthy System
Volume 1 C NTFS Mirror 141 GB Failed Rd Boot
Volume 2 D System Rese NTFS Simple 100 MB Healthy
Technically, scripting diskpart is a bit cumbersome, as the creators of the tool want you to specify any commands to pass to diskpart in a text file, and in turn specify that text file with the /s parameter. This makes sense, since diskpart can automate partitioning, which can certainly result in a dozen or so commands.
For our purposes however it’s overkill, so we can trick diskpart by running a single command:
echo list volume | diskpart
which will yield the same results as above, without the need of an “instruction” file.
The easy way out
The quickest way (though per usual not the most elegant) to get RAID notifications is to create a batch file (e.g. list_raid.cmd) with the content shown earlier
echo list volume | diskpart
and execute the script on a regular basis (e.g. every minute) which will result in the output of the diskpart command being logged to the event log as event 10200.
Then, you can create an include filter in an event log package, which will look for the following string:
*DISKPART*Status*Failed Rd*
If your EventSentry configuration is already setup to email you all new errors then you don’t even have to setup an event log filter – just creating the script and scheduling it will do the trick.
But surely you will want to know how this can be accomplished in a more elegant fashion? Yes? Excellent, here it is.
A Better Solution
One problem with the “easy way out” is that it will not detect all Non-Ok RAID statuses, such as:
• At Risk
• Rebuild
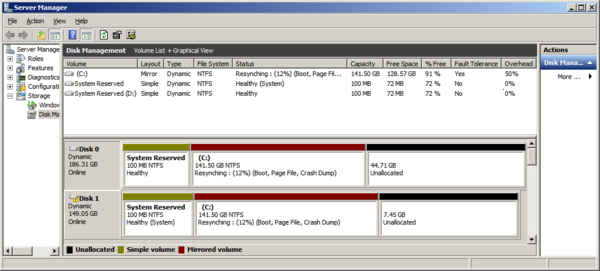 Furthermore, the output can be rather verbose, and will include any logical drive, include CD-ROMs, removable disks and others.
Furthermore, the output can be rather verbose, and will include any logical drive, include CD-ROMs, removable disks and others.
It is for this reason we have created a VBScript, which will parse the output of the diskpart command with a regular expression, and provide the following:
• A filtered output, showing only drives in a software raid
• Formatted output, showing only relevant drive parameters
• Detecting any Non-Healthy RAID
Alas, an example output of the script is as follows:
Status of Mirror C: (Boot) is "Healthy"
Much nicer, isn’t it? If a problem is detected, then output will be more verbose:
**WARNING** Status of Mirror C: (Boot) is "Failed Rd"
WARNING: One or more redundant drives are not in a “Healthy” state!
The VBScript will look at the actual “Status” column and report any status that is not “Healthy”, a more accurate way to verify the status of the RAID.
Since the script has a dynamic ERRORLEVEL, it’s not necessary to evaluate the script output – simply evaluating the return code is sufficient.
Implementation
Let’s leave the theory behind us and implement the solution, which requires only three steps:
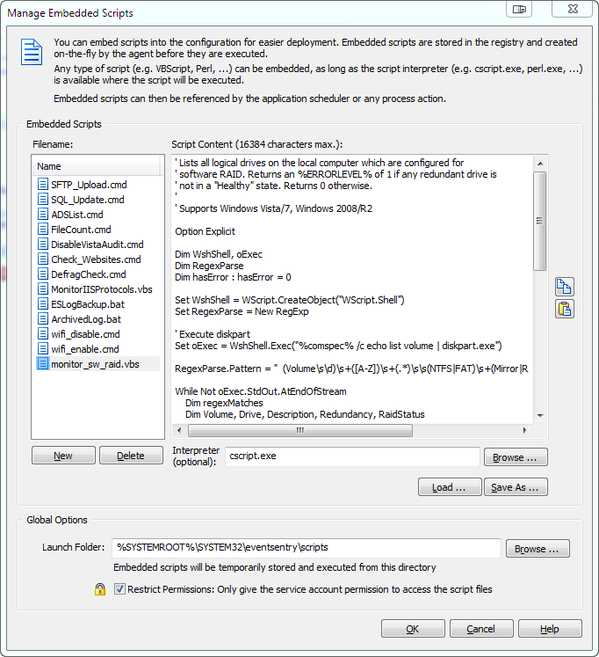
1. Create an embedded script (we will include this script with v2.93 by default) through the Tools -> Embedded Scripts option, based on the VBScript below. Select “cscript.exe” as the interpreter. Embedded scripts are elegant because they are automatically included in the EventSentry configuration – no need to manage the scripts outside EventSentry.
 2. Create a new System Health package and add the “Application Scheduler” object to it. Alternatively you can also add the Application Scheduler object to an existing system health package. Either way, schedule the script with a recurring schedule.
2. Create a new System Health package and add the “Application Scheduler” object to it. Alternatively you can also add the Application Scheduler object to an existing system health package. Either way, schedule the script with a recurring schedule.
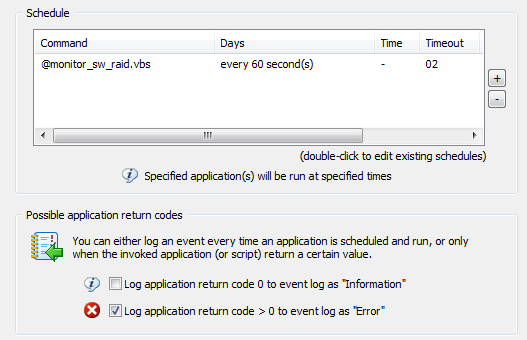 Note that commands starting with the @ symbol are embedded scripts. The “Log application return code 0 to event log …” option is not selected here, since the script runs every minute and would generate 1440 entries per day. You may want to enable this option first to ensure that your configuration is working, or if you don’t mind having that many entries in your application log. It’s mainly a matter of preference.
Note that commands starting with the @ symbol are embedded scripts. The “Log application return code 0 to event log …” option is not selected here, since the script runs every minute and would generate 1440 entries per day. You may want to enable this option first to ensure that your configuration is working, or if you don’t mind having that many entries in your application log. It’s mainly a matter of preference.
3. This step is optional if you already have a filter in place which forwards Errors to a notification. Otherwise, create an event log filter which looks for the following properties:
Log: Application
Severity: Error
Source: EventSentry
ID: 10200
Text (optional): “WARNING: One or more redundant drives*”
The VBScript
' Lists all logical drives on the local computer which are configured for
' software RAID. Returns an %ERRORLEVEL% of 1 if any redundant drive is
' not in a "Healthy" state. Returns 0 otherwise.
'
' Supports Windows Vista/7, Windows 2008/R2
Option Explicit
Dim WshShell, oExec
Dim RegexParse
Dim hasError : hasError = 0
Set WshShell = WScript.CreateObject("WScript.Shell")
Set RegexParse = New RegExp
' Execute diskpart
Set oExec = WshShell.Exec("%comspec% /c echo list volume | diskpart.exe")
RegexParse.Pattern = "\s\s(Volume\s\d)\s+([A-Z])\s+(.*)\s\s(NTFS|FAT)\s+(Mirror|RAID-5)\s+(\d+)\s+(..)\s\s([A-Za-z]*\s?[A-Za-z]*)(\s\s)*.*"
While Not oExec.StdOut.AtEndOfStream
Dim regexMatches
Dim Volume, Drive, Description, Redundancy, RaidStatus
Dim CurrentLine : CurrentLine = oExec.StdOut.ReadLine
Set regexMatches = RegexParse.Execute(CurrentLine)
If (regexMatches.Count > 0) Then
Dim match
Set match = regexMatches(0)
If match.SubMatches.Count >= 8 Then
Volume = match.SubMatches(0)
Drive = match.SubMatches(1)
Description = Trim(match.SubMatches(2))
Redundancy = match.SubMatches(4)
RaidStatus = Trim(match.SubMatches(7))
End If
If RaidStatus <> "Healthy" Then
hasError = 1
WScript.StdOut.Write "**WARNING** "
End If
WScript.StdOut.WriteLine "Status of " & Redundancy & " " & Drive & ": (" & Description & ") is """ & RaidStatus & """"
End If
Wend
If (hasError) Then
WScript.StdOut.WriteLine ""
WScript.StdOut.WriteLine "WARNING: One or more redundant drives are not in a ""Healthy"" state!"
End If
WScript.Quit(hasError)
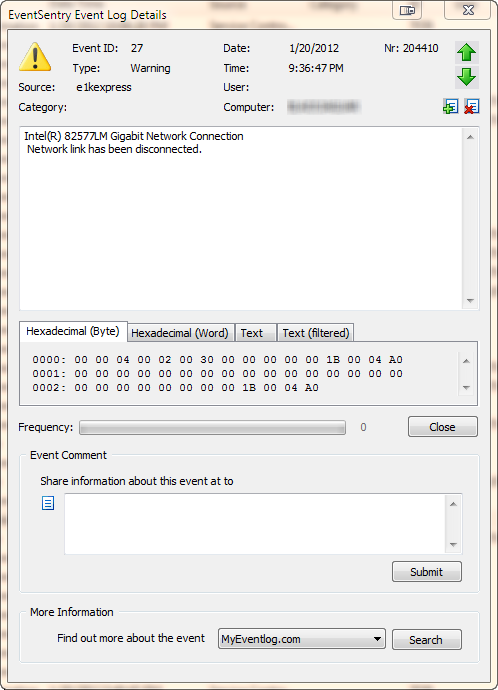 A similar event is logged when the “network link” has connected. The event shown here is specific to the driver of my laptop’s network card (an Intel(R) 82577LM adapter), but most newer drivers will log events when a cable is disconnected or the link is otherwise lost. If you are already running EventSentry with its hardware inventory feature enabled, then you can obtain the name of the network adapter from any monitored host on the network through the hardware inventory page, an example is shown below.
A similar event is logged when the “network link” has connected. The event shown here is specific to the driver of my laptop’s network card (an Intel(R) 82577LM adapter), but most newer drivers will log events when a cable is disconnected or the link is otherwise lost. If you are already running EventSentry with its hardware inventory feature enabled, then you can obtain the name of the network adapter from any monitored host on the network through the hardware inventory page, an example is shown below. Coming up with a way to enable and disable a particular network connection with netsh.exe was a bit more challenging, but I eventually cracked the cryptic command line parameters of netsh.exe.
Coming up with a way to enable and disable a particular network connection with netsh.exe was a bit more challenging, but I eventually cracked the cryptic command line parameters of netsh.exe.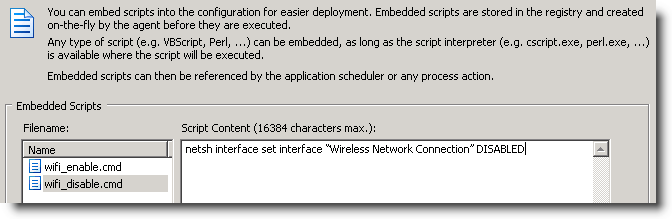 Actions
Actions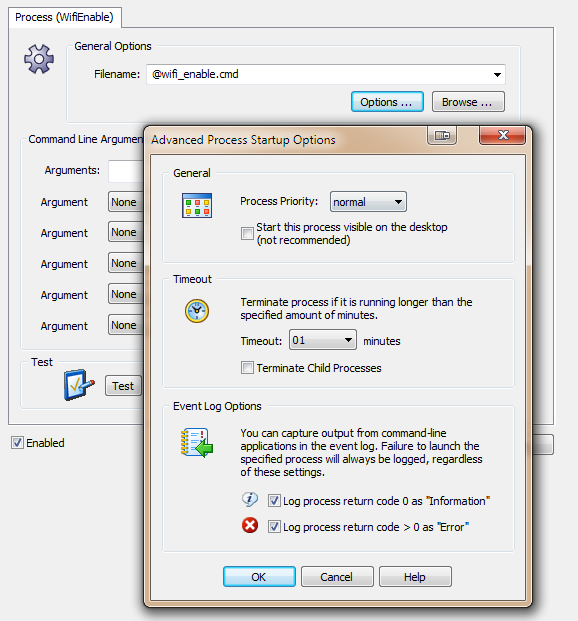 I recommend enabling both “Event Log Options”, as this will help with troubleshooting. Now we just need the event log filters, and we are all set.
I recommend enabling both “Event Log Options”, as this will help with troubleshooting. Now we just need the event log filters, and we are all set.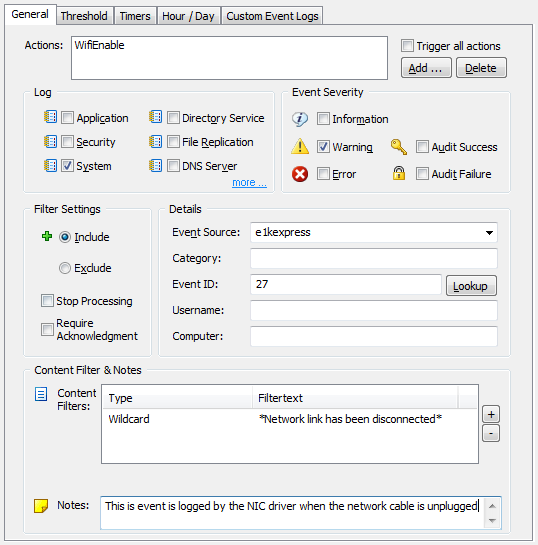 That’s pretty much it. If you enabled the event log options in the process action earlier, then you can see the output from the process action in the event log, as shown below:
That’s pretty much it. If you enabled the event log options in the process action earlier, then you can see the output from the process action in the event log, as shown below: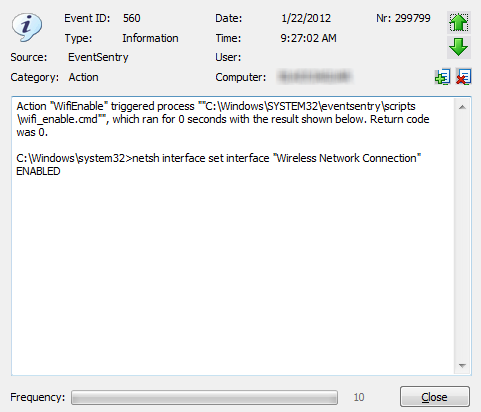 Here are some links to the official EventSentry documentation regarding the features used:
Here are some links to the official EventSentry documentation regarding the features used: