Our latest patch for EventSentry v3.2 (v3.2.1.30) requires some additional information in addition to the release notes.
Heartbeat Monitoring (Agent Status) By default, the EventSentry Heartbeat Monitor ensures that all remote agents are running by querying the status of the remote “EventSentry” service. While is an accurate way to ensure the remote agent is running, the Microsoft RPC mechanism isn’t very efficient when connecting to remote hosts across a slow (WAN) link, and concurrently checking the service status of 100+ hosts at the same time can on occasion also cause issues. In these situations, the heartbeat agent may not be able to monitor all hosts in the configured monitoring interval. Furthermore, querying the remote status of a service requires that the EventSentry Heartbeat Agent run under a domain account, otherwise the dreaded “Access Denied” error appears on the heartbeat status page in the web reports.
To address these issues for larger EventSentry deployments (500+ hosts) and deployments where the remote agents are connected through a slower WAN link, we have added the ability to query the remote agent status through the EventSentry database where the remote agents periodically check in. This check is enabled by default for new installations, but existing installations will need to make a database permission change in order to give the heartbeat agent permission to query the agent status. More information can be found here.
In the next release of EventSentry (v3.3), this functionality will be configurable, and the heartbeat agent will also be able to determine the current agent status by communicating directly with the collector service (when enabled) for even better accuracy. The Heartbeat Monitor will always attempt to revert back to the legacy method of checking the service status directly if it cannot obtain the status through other means.
Service Monitoring: Configuration Changes EventSentry distinguishes between three types of service changes: Status changes (e.g. Running to Stopped), service configuration changes (e.g. changes to the startup type) and services being added or removed. Up until release 3.2.1.22, all status changes and service configuration changes were logged with the same event severity, which we didn’t think was very fitting since the status change of a service is very different to a change of the service itself. As such, starting with 3.2.1.30, only service status changes will be logged under the severity configured under “Monitor Service Status Changes” category. All other service changes will be logged under the severity configured under “Monitor Service Addition / Removal” category.
Management Console: Quicktools
The EventSentry QuickTools allow you to run an application/script against a server or workstation in your EventSentry configuration. EventSentry includes a few default QuickTools entries, such as “Reboot”, “Remote Desktop” and others. Starting with the latest release we added a new “Hide” option, which will not show the executed application on the desktop. This will be useful for integrating our upcoming VNC wrapper scripts (Blog article coming soon), which will allow you to install & launch a (Tiger)VNC client directly from the EventSentry management console.
EventSentry Light 3.2 Starting with this release, EventSentry Light v3.2 will also be available. We have good news for all EventSentry Light users: We have increased the number of full hosts you can remotely manage to 5, and also increased the number of network devices you can monitor to 5. As such you can now monitor up to 10 hosts with EventSentry Light completely for free.
There seems to be a new variant of ransomware popping up somewhere every few months (Locky being the most recent one), with every new variation targeting more users / computers / networks and circumventing protections put in place by the defenders for their previous counterparts. The whole thing has turned into a cat and mouse game, with an increasing number of software companies and SysAdmins attempting to come up with effective countermeasures.
I’ve already proposed two ways to counteract ransomware on file servers with EventSentry in part 1 and part 2, both of which take a little bit of time to implement (although I’d argue less than it would take to restore all of your files from backups). The last part of the series, remediation, offers a way to remotely log off an infected user. In this post I’m proposing a third, and better, method with the following improvements:
In the first article we configured file integrity monitoring on a volume, and if the number of file modifications occurring during a certain time interval exceeded a preset threshold, the ransomware would be stopped in its tracks. In the seconds article we used bait (canary) files to accomplish the same thing.
In this third installment we’ll keep track of the number of file modifications made by a user to detect if an infection is underway. To effectively defeat ransomware, we have to be able to distinguish between legitimate user activity and an infection. To date we know this:
Users add/change/remove files, but the number of changes made by a user in a short amount of time (say 15 min) is generally small
Ransomware always runs in the context of a user, and as such an infection will usually come from one user (unless things go really awry and multiple users are infected). The approach here will work equally well, regardless of the number of infections.
Thus, to detect an infection, EventSentry will be counting the number of file modifications (event 4663) with its advanced threshold capabilities. If the threshold is exceeded, EventSentry will trigger an action of your choice (e.g. disable the user, remove a file share, stop the server service, …) to limit the damage of the ransomware.
Here is what you need:
Object Access / File System Auditing enabled
Auditing enabled on the files which are to be protected
EventSentry installed on the server which needs to be protected
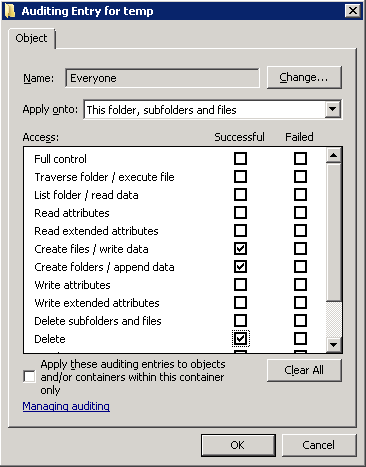
This KB article explains how to configure EventSentry and enable auditing (preferably through group policy) on one or more directories. I recommend referencing the KB article when you’re ready to configure everything. Pretty much everything in the KB article applies here, although we will make a small change to the threshold settings of the filter (last paragraph of section (4)).
Windows Folder Auditing
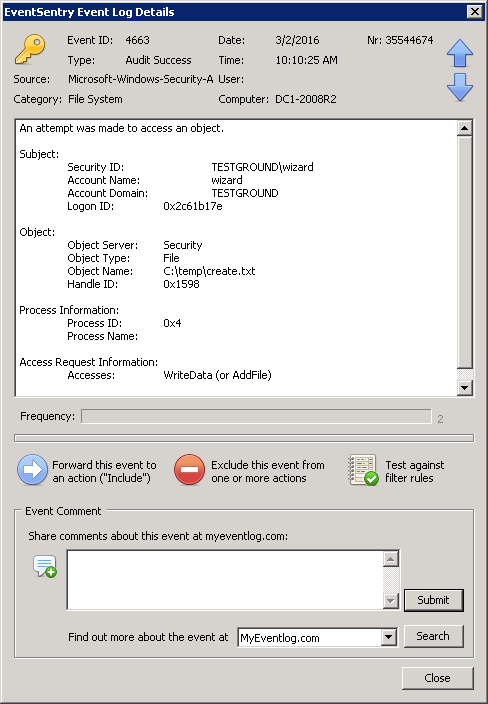
Once auditing is setup, Windows will log event 4663 for every write access which is performed by a user. An example event looks like this:
Windows Event 4663
The default behavior of a filter threshold in EventSentry is to simply count every filter match towards the threshold. In our case, every 4663 event encountered would count towards the threshold. You can think of there being one bucket for all 4663 events, with the bucket being emptied whenever the threshold period expires, say every 5 minutes. If the bucket fills up we can trigger an alert.
This doesn’t work so well on a file server, where potentially hundreds of users are constantly modifying files. It would take some time to come up with a good baseline (how many file modifications are considered “normal”) that we could use as a threshold, and there would still be a chance for a false positive. For example, a lot of 4663 events could be generated during a busy day at the office, thus causing the threshold to reach its limit.
A better way is to assign each user their own “personal” threshold which we can then monitor. Think of it like each user having their own bucket. If a user writes to a file, EventSentry adds the 4663 event only to that user’s bucket. Subsequently, an alert is only triggered when a user’s bucket is full. Any insertion string of an event can be used to create a new bucket.
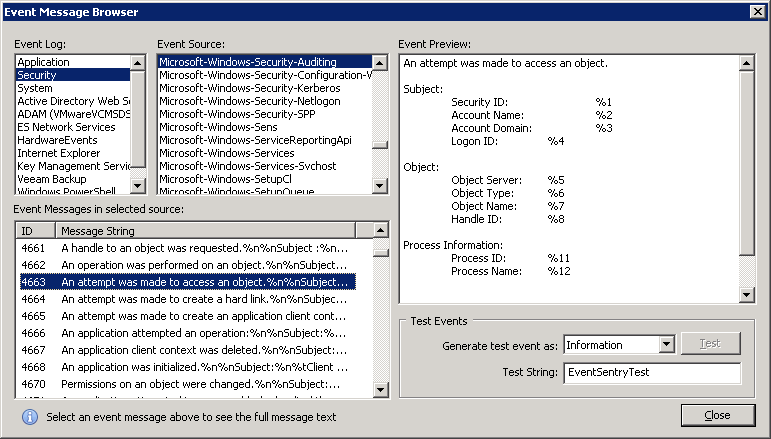
We can do this by utilizing the insertion string capabilities of the filter threshold feature. Setting this up is surprisingly easy – all we have to do is change the Threshold Options to “Event”, click the “Insertion Strings” button and select the correct insertion string. What is the correct insertion string? The short answer is #1.
The long answer lies in the “Event Message Browser”, which you can either find through the Tools – Utilities menu in the EventSentry Management Console or in the EventSentry SysAdmin Tools. Once in there, click on “Security”, then “Microsoft-Windows-Security-Auditing”, then 4663. You will see that the number next to the field identifying the calling user (“Security ID”) is %1.
Event 4663 Definition
Enough with the theory, here is what you need to implement it (assuming EventSentry is already installed on the servers hosting the file share(s)):
Determine what action you want to take when a ransomware infection has been detected. See either section 1 of KB 279 or “Dive! Stopping the Server Service” from the previous blog post.
Create a package & filter looking for 4663 events. See section 4 of KB 279 and review the additional threshold settings below.
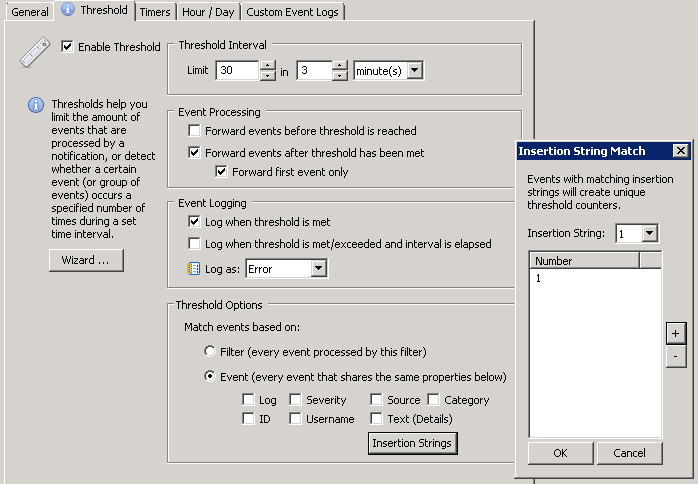
Customizing the threshold Once you have the package & threshold filter for 4663 events in place, we need to modify the threshold settings as explained above. Edit the filter, click the threshold tab and make sure your filter looks like the one shown below:
Threshold Settings
The only variable setting is the actual threshold, since it depends on how fast the particular variant of ransomware would be modifying files. A couple of things to keep in mind:
The interval shouldn’t be too long, otherwise it will take too long before the infection is detected.
Make sure the actual event log filter is only looking at 4663 events, no other event ids.
With the above example, any user modifying any file (on a given server) more than 30 times in 3 minutes will trigger any action associated with the filter, e.g. shutting down the server service. Note that the action listed in the General tab will be triggered as soon as the threshold is met. If 30 4663 events for a single user are generated within 45 seconds, the action will be triggered after 45 seconds, it won’t wait 3 minutes.
Bonus – Disabling a user One advantage of intercepting 4663 events is that we can extract information from them and pass them to commands. While shutting down the Server service is pretty much essential, there are a few other things you can do once you have data from the events, e.g. the username, available. You can now do things like:
Disabling the user
Removing the user from the share permissions
Revoking access to select folders for the user
There are a couple of caveats when (trying to) disable a user however:
The user account (usually the computer account) under which the EventSentry service runs under (usually LocalSystem) needs to be part of the Account Operators group so that it has permission to disable a user
Disabling a user is usually not enough though, since Windows won’t automatically disconnect the user or revoke access. As such, any ransom/crypto process already running will continue to run – even if the user has been disabled.
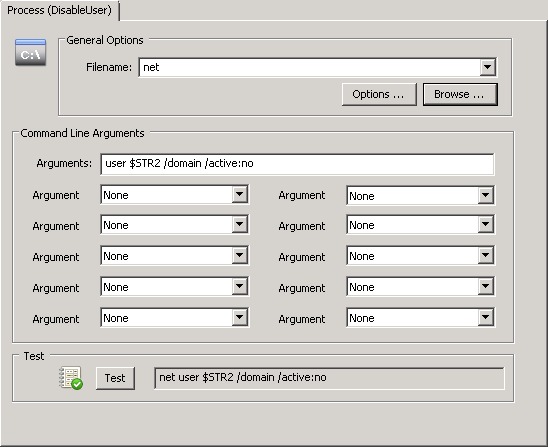
Disabling a user account from the command line is surprisingly simple (leave Powershell in the drawer). To disable the user john.doe, simply run this command:
net user john.doe /domain /active:no
Note that since “net user” doesn’t support a domain prefix (MYDOMAIN\john.doe won’t work), we need to make sure that we pass only the username (which is insertion string %2) and the /domain switch to ensure the user is disabled on the domain controller. Of course you would need to omit the /domain switch if the users connecting to the share are local users. The action itself would look like the screenshot below, where $STR2 will be substituted by EventSentry with the actual user listed in the event 4663:
Action to disable a user
That’s it, now just push the configuration and you should be much better prepared to take any ransomware attacks heading your users way.
I am e-x-c-i-t-e-d to announce the availability of EventSentry v3.2 and tell you more about the new features and improvements. So, if you’re looking for a little bit more than the release notes then read on!
Collector The biggest new feature in 3.2 is the collector, a new central component which enables a 3-tier architecture in EventSentry. Traditionally, the EventSentry agents have been communicating directly with email servers, databases and other services. While this usually worked well – and is still desirable in many setups – it does impose a limitation in some scenarios:
The SMTP server cannot be configured to allow relaying and/or accepting SMTP connections from remote clients
The central database cannot be configured to allow connections from remote clients
Agents need to communicate over an insecure medium like the Internet
The collector addresses the above limitations by acting similar to a proxy between the remote agents and the service (e.g. database). In a nutshell, it provides the following benefits:
Agents only communicate with the collector over a single port
All traffic can be encrypted and compressed
Database connection details do not need to be stored on the agents anymore
All collected data is cached on the agents if and while the collector is unreachable
Whether you will need the collector or not will largely depend on your network setup. If all of your hosts are in the same data center and/or the same LAN, the collector may provide little benefit. If you are a MSP and monitoring remote sites and laptops however, then the collector is probably what you have been waiting for!
When upgrading (or installing from scratch), the post-installer configuration assistant will ask you whether you are interested in enabling the collector.
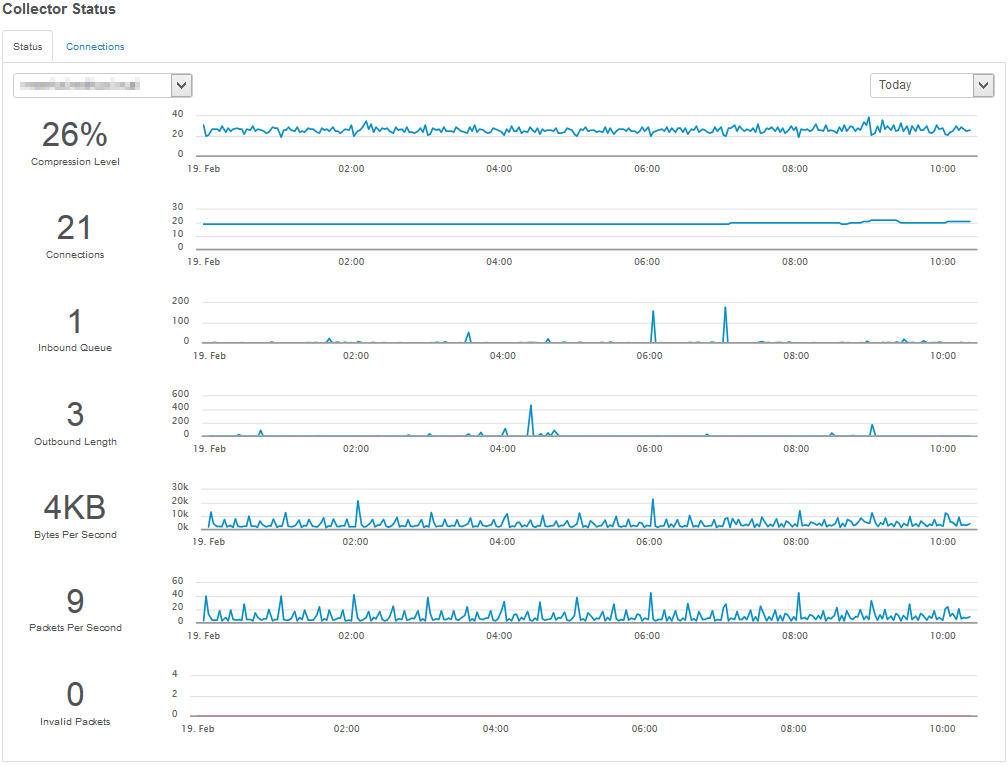
Collector Status in maintenance menu
If you are installing from scratch, then enabling the collector during the installation is all you need to do. When upgrading, an additional step is required – an action needs to be configured to use the collector. While the collector service is installed & started during the upgrade when selected, it will not enable any of the existing actions to use the collector. As such, if you want to route data for a specific action through the collector, that needs to be configured. Simply edit the action and click the “Use Collector” check box on the bottom left and push the configuration.
In version 3.2.1, the following actions can be routed through the collector:
Database
Email (SMTP)
Syslog
Text File
Since the collector, when enabled, is a critical component, we recommend monitoring the collector stats either through the collector status page (Maintenance -> Collector Status) or by adding the collector status tile to one of your dashboards.
There is one other advantage the collector can bring when routing emails through it:
Emails from multiple hosts can be grouped together (if the action polling interval is sufficiently high)
Action thresholds can now be applied centrally
Both features can help reduce the number of emails you receive from EventSentry, usually a popular thing to do!
Compliance Modules
EventSentry has always included the compliance tracking components which monitor and interpret Windows security events. Compliance tracking provides process, console, account management and other tracking reports. While popular and extremely useful, the compliance reports themselves don’t tell the user which particular compliance requirement they address.
Say Hello to the new compliance modules, which provide detailed, out-of-the-box reports for:
PCI-DSS
FISMA
HIPAA
GLBA
Sarbanes Oxley
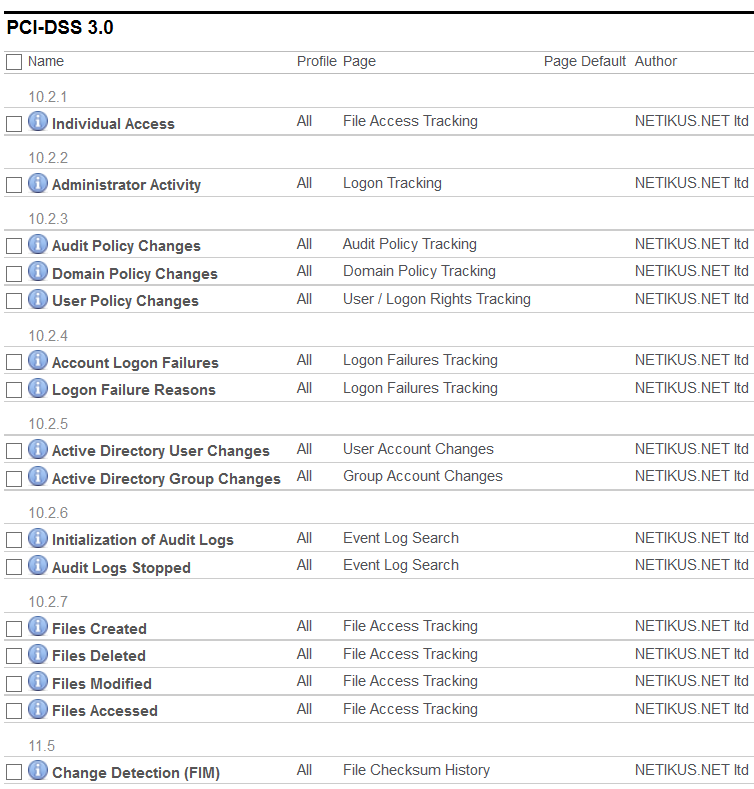
Once a compliance module is enabled, it will install a number of reports that pertain to the specific compliance requirement that was enabled. Every report will be associated with a specific control (e.g. PCI 10.2.2) and allow you to setup a required review, job and more.
Example of PCI compliance reports
(Network) Switch Mapping Finding the port on a switch to which a server, workstation or network device is connected is often a time-consuming and annoying process for most SysAdmins. Starting with version 3.2, EventSentry tries to ease that pain by showing exactly to which switch – and port – a host is connected to. All you need to do is add the switch to the EventSentry configuration, make sure that it can be monitored via SNMP and that it provides the MAC to port mappings via SNMP (OID 1.3.6.1.2.1.17.4.3.1.2 – iso.identified-organization.dod.internet.mgmt.mib-2.bridge.dot1dTp.dot1dTpFdbTable.dot1dTpFdbEntry.dot1dTpFdbPort). This feature should work well with all mainstream managed switched, and we haven’t run into a switch yet where this feature wasn’t provided or did not work.
Server Room Cables
Once EventSentry pulls the MAC to Port mappings, you will be able to retrieve the collected information in two ways:
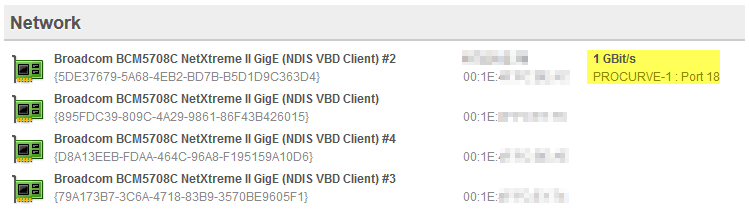
Through the Inventory – Switch page, which will show all monitored switches and connected devices
Through the Inventory – Host page. If the switch port can be detected, it will be displayed next to the IP address of the network card
Since switches only provide MAC addresses, EventSentry attempts to map MAC addresses to host names and IP addresses by analyzing the hardware inventory details as well as the ARP status table when available. As such, it is recommended to enable the ARP component of the network services if the results on your switch inventory page are incomplete.
EventSentry Switch Port Indicator
Web Reports Improvements
Starting with a visual overhaul of the interface, the web reports also received an internal overhaul to improve overall performance, especially when using multiple profiles. The performance trends page can now display multiple charts on a single page, and the host inventory page now shows the highest supported USB version on that host.
Managing multiple reports is easier now through the ability to bulk-edit reporting settings. Reports can now also be saved to a folder instead of being emailed.
Finally, the web reports are now also officially available in 6 additional languages: French, Spanish, Polish, Portuguese, Dutch and Italian. This brings the total number of supported languages in the web reports to 9!
Management Console Improvements
Improvements in the management console pertain mostly to remote update and computer management. Hosts can now be imported from a network scan, which is particularly useful when managing network devices which often don’t show up in Active Directory. The network scan is multi-threaded and can scan a class C subnet in a few seconds and even supports checking TCP ports for hosts which have ICMP disabled.
Remote update can now store the result of every activity in CSV file(s), and output from remote update can be toggled with the context menu to apply remote update actions to a sub-set of hosts easily.
Also new is the ability to export all event log filters to a CSV file allowing you to analyze the results in your favorite spreadsheet application to identify issues, duplicates etc.
In the ideal world, every software we install on our servers and workstations uses as few resources as possible, doesn’t have memory or handle leaks and never crashes.
But in reality, Sysadmins often have to deal with temperamental business-critical third-party applications (or in-house developed) which exhibit a number of issues, including:
Memory Leak: The application keeps eating away at the available memory like a chubby caterpillar chewing on a leaf
Handle Leak: The application continuously increases its handle count, which takes away from kernel memory over time
CPU Spike: The application uses all CPU time of one or more cores
When one of these issues is encountered, a manual application (or service) restart, along with a potential bug report, is usually the only solution. Consequently, keeping a close eye on both Windows and third-party software – especially on servers – is considered good practice. But even better than looking is being proactive of course, for example by automatically restarting a service which uses too much memory or CPU.
This is where EventSentry comes in. EventSentry doesn’t just analyze metrics available through Windows performance counters (e.g. CPU usage, handle or memory count of a process.), it also allows you to take corrective action based on granular rule sets. This ensures that all active applications are behaving nicely by staying within pre-defined performance boundaries.
To get there, we utilize 3 features in EventSentry:
Since examples usually work best, I will outline the steps required to restart the printer spooler service if it uses more than 100 Mb of RAM. This is for illustration purposes only, I’m not suggesting that the printer spooler service should not use more than 100 Mb of RAM.
Performance Monitoring
Application performance monitoring is already setup out-of-the-box via the “Performance Applications” System Health package. This package, by default, is assigned to all hosts and collects key application metrics in the EventSentry database. Since this package is generic and captures all processes (without generating alerts), we’ll create a separate package that will only monitor the spooler service.
Unless you resort to scripting, it is unfortunately not easily possible to automatically link process names (as they are reported by the Windows performance monitoring subsystem) to a service name. As such, we will need to first find out the process of the service we are monitoring and then monitor only that instance of the performance counter. To determine the process for a given service, simply view the properties of the services in the “Services” or “View local services” application and look for the “Path to executable” field. New versions of Windows also show a list of all services in task manager and let you jump to the process by clicking on “Go to details”. The name of the instance is the process name without the .exe extension, spoolsv in this case.
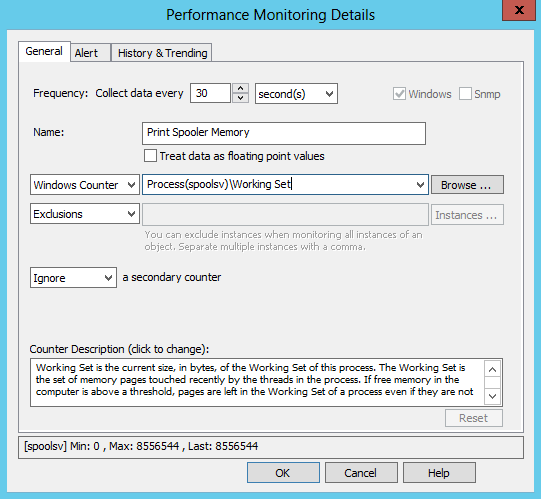
The next step is to create a new System Health package and add a performance object. Select the System Health packages container, click “Add package” from the ribbon and enter a suitable name. Select the newly created package and add the performance object to the package. Now select the “Performance” object and click the “+” icon to add a new performance object to monitor. Every performance object in EventSentry requires at least a name (to describe the counter) as well as the actual Windows performance counter. The respective performance counter for monitoring the memory usage of a process is Process(*)\Working Set, and since we are only interested in the spooler process we will use of the Process(spoolsv)\Working Set performance counter. When you are done, the dialog should look similar to what is shown below:
Specifying the performance counter to monitor the memory usage of the spooler process
The default frequency is 10 seconds which works well for most counters, but you can increase this frequency for counters which change only minimally over the short term (as is usually the case for memory usage and handle count), so we will use 30 seconds in this case.
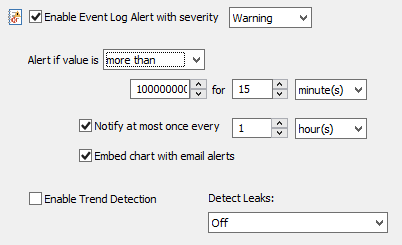
Now that we are successfully tracking the memory usage of the spooler service, we need to setup a hard limit in order to get an event when that limit is exceeded. Click on the “Alert” tab and configure the dialog as shown below:
Specifying the alert limit for the performance counter
We are only concerned with the top section of the dialog, please see the documentation for more details on the “Notify at most …” and below options.
The last step in this section is to assign the package: Select the package, click “Assign” in the ribbon and assign the package to a computer or group. EventSentry is now tracking the memory usage of the spoolsv process and will log a warning event if the memory usage exceeds 100 Mb.
Action
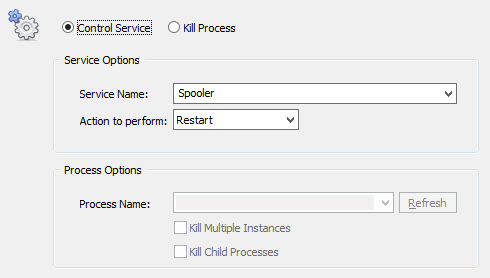
EventSentry uses actions to send emails, toggle services or start processes. Since we want to restart the spooler service, we’ll create a Service action. Select the “Actions” container and click the “Add” button. Select the “Service” action type and assign it a descriptive name, e.g. “Restart Print Spooler Service”.
The configuration of this action is probably the most simple in this tutorial – just specify the service name and the desired action as shown below:
Specifying the service to be restarted
Connecting the dots: Event Log Filter
We’re monitoring the memory usage of the spooler now and have an action which can restart the spooler service, but how do we connect the two? You probably guessed it – with an event log filter. Event Log filters allow you to connect an event (e.g. memory usage is too high) with an action (e.g. restart spooler service).
We’ll create an event log filter which will look for the exact event that is being logged when the memory usage of our performance counter exceeds 100 Mb, and trigger the service restart action.
Similar to what we did with the system health package, right-click the “Event Log Packages” container (or use the ribbon) to create a new event log package and assign it to the computer(s) and or group(s) in question.
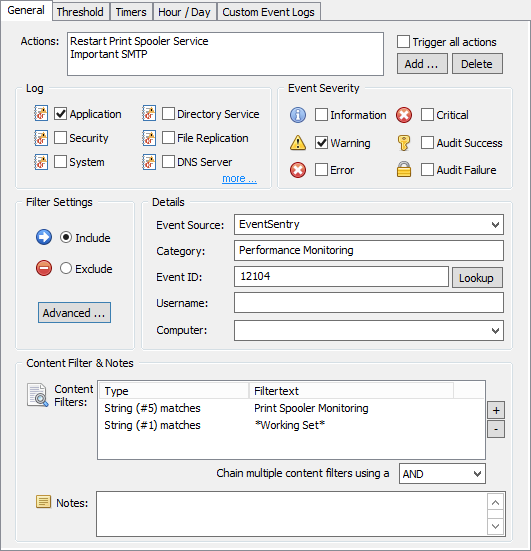
Then, add a new INCLUDE filter to the package. Alternatively you can also click the “Alerts” button while the performance object is selected to go through a wizard. Either way, the filter should look like the screenshot below:
Specifying the event properties which will trigger the service restart action
Now, when the performance monitor writes event id 12104 with the above properties, EventSentry will trigger the “Restart Print Spooler Service” action which should reset the memory usage of the process. As an added bonus, an email is also fired off so that the operator knows that EventSentry took the corrective action.
Note: Don’t forget to push the configuration to any remote hosts if necessary.
Now sit back and relax knowing that another thing is taken care of for you.
I’m excited to announce a new version of our free EventSentry SysAdmin Tools which, in addition to bug fixes and minor improvements, also includes a new command-line tool: snmptool. This brings the total number of utilities in the toolkit to thirty (30)!
Free SNMP tools for Windows® are not easy to find and often require you to memorize the various OIDs in order to test a remote host’s SNMP functionality, or to get useful information back.
Our free snmptool utility solves that problem by giving you a simple utility which downloads a variety of stats, depending on what the remote host provides via SNMP, and displays it to the user. For example, if you are querying a VMWare® ESXi™ host with the snmptool, it will – among other stats – enumerate all VMs configure on the host, whereas it will display switch port mappings when querying a switch.
The snmptool currently retrieves the following:
System Description string
Operating System
Uptime
Current CPU usage
Network interfaces (name, MAC address, IP if available)
Mounted disks
Running processes
Virtual Machines (ESXi™ only)
Switch port mappings
Running the utility is incredibly easy, simply specify the SNMP credentials and the remote host, and the utility will do the rest on its own:
C:\>snmptool /u public linuxserver
System Description: Linux openvas.netikus.local 4.32.22-573.7.1.el6.x86_128 #1 SMP Tue Sep 22 22:00:00 UTC 2019 x86_128
OS Info: Linux 4.32.22-573.7.1.el6.x86_128 #1
Current Uptime: 3 years, 321 days, 3 hours and 52 minutes
CPU Usage: 0%