In my previous post I talked about our new NetFlow component as well as the new agent management capabilities now available in EventSentry v3.3. In this post I’ll cover the remaining new features and improvements we’ve made in v3.3, starting with the web reports.
Web Reports
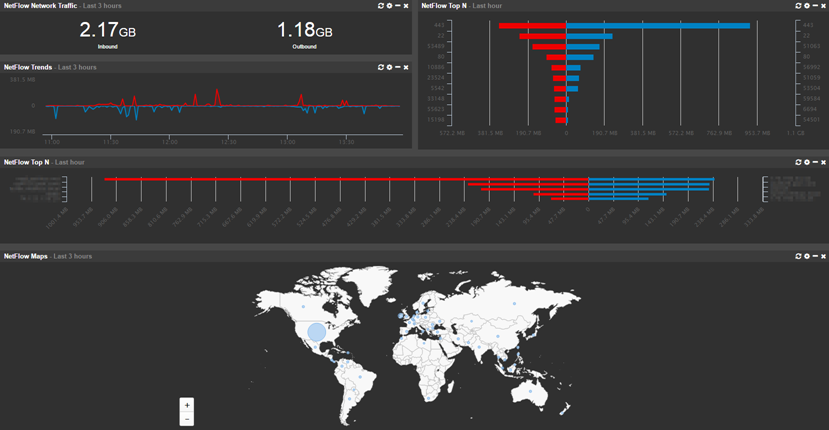
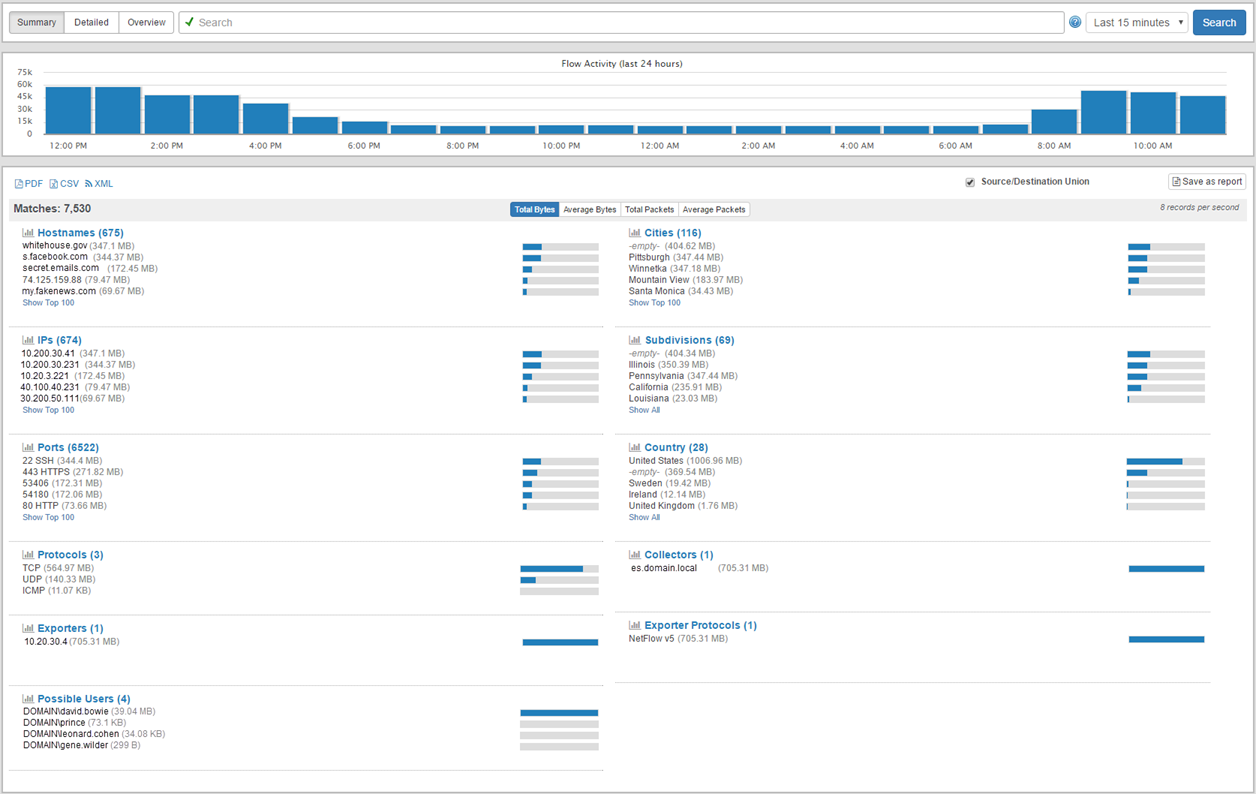
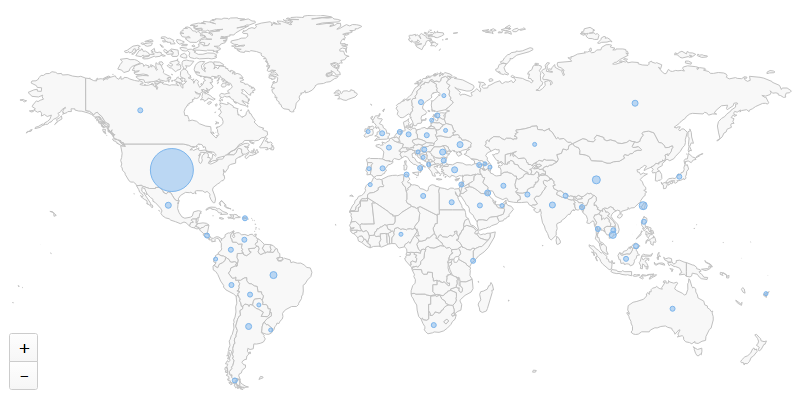
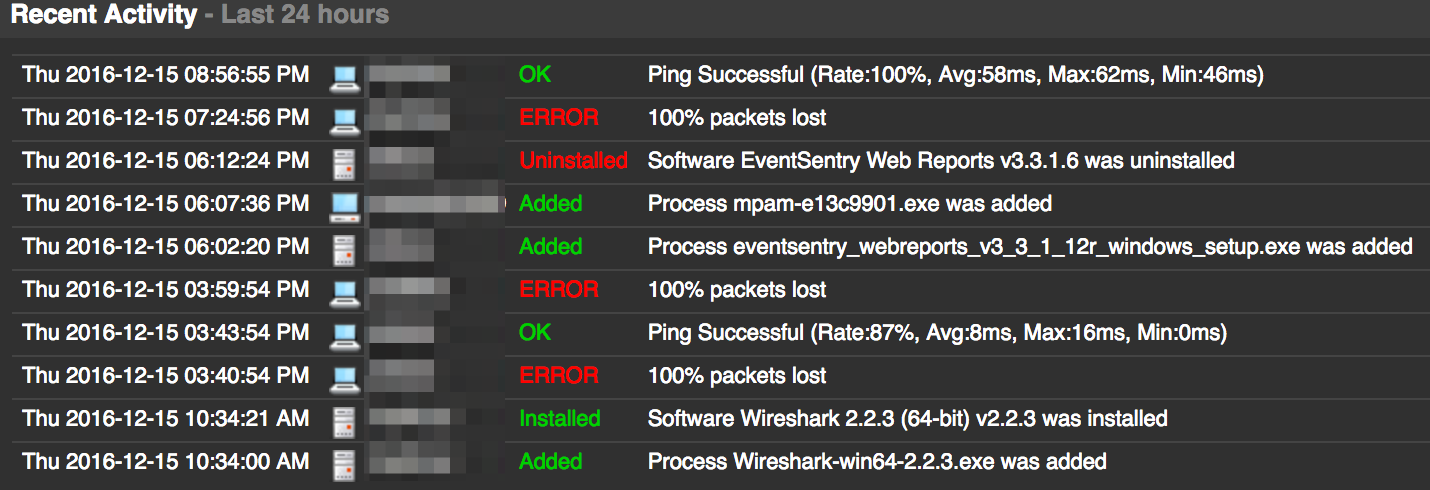
There are a number of new features and improvements in addition to NetFlow visualization. There are a few new dashboard tiles, including a “Recent Activity” tile which – as the name implies – shows recent relevant changes such as newly detected processes, software (un)installed, ping status or service status changes.
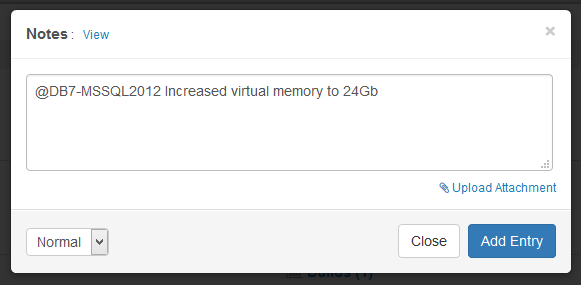
Anybody who works in a team of two or more Sysadmins should find the new notes feature incredibly helpful. It lets any web reports user add comments (=notes) which are subsequently visible to others. Notes can be associated with one or more hosts (ensuring they show up in the “Documentation” tab of the respective host status page) and can include documents as attachments as well! Do you have warranty documents or network diagrams you want to store in a central place – easily accessible? That’s what the notes are for.
The overall look and feel has also been refreshed, and we’ve reorganized the menu to make it faster to access dashboards and easier to find pages.
The visualization of data has been improved, since some chart types work better with certain features of EventSentry. You can now visualize grouped data using either pie charts, tree maps or column charts.
The security of the web reports has also improved with a lockout policy which will locking an account after too many unsuccessful logon events.
Monitoring Improvements
As mentioned in part 1, the EventSentry is agent is now available in 64-bit, making it possible to monitor 64-bit counters and easier to monitor files in 64-bit directories. For users upgrading from an earlier version, the EventSentry management console will automatically migrate any existing 32-bit agents on 64-bit versions of Windows.
Application & Services Event Logs
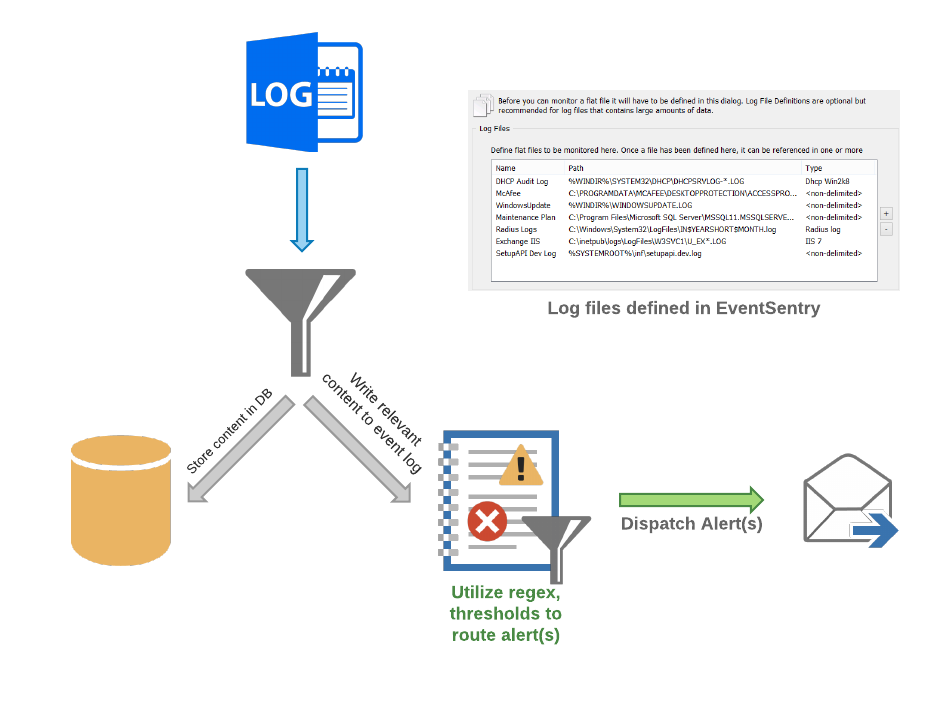
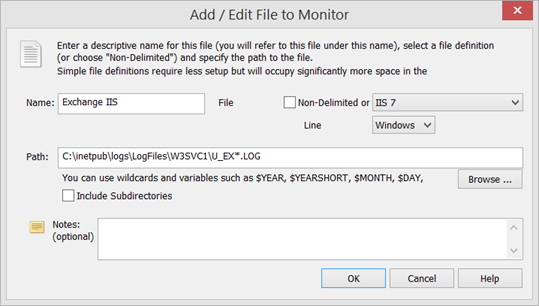
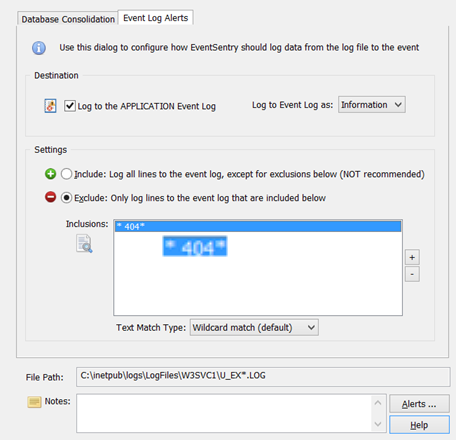
While monitoring Application & Services event logs, often referred to as “custom” event logs was possible, the way this needed to be configured in the management console was a common source of confusion. Some users also needed the ability to monitor more than 30 different logs. Consequently, monitoring additional event logs is now straightforward, and users can monitor as many event logs as they wish.
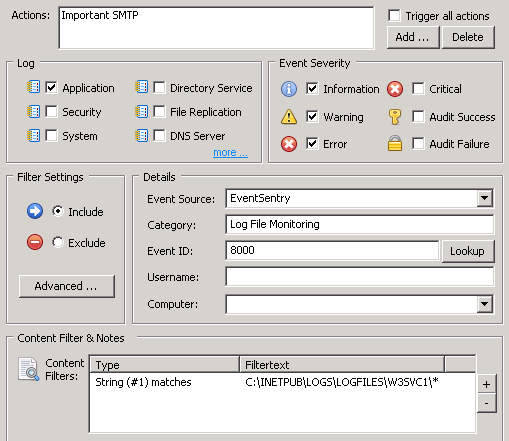
Filter Chaining
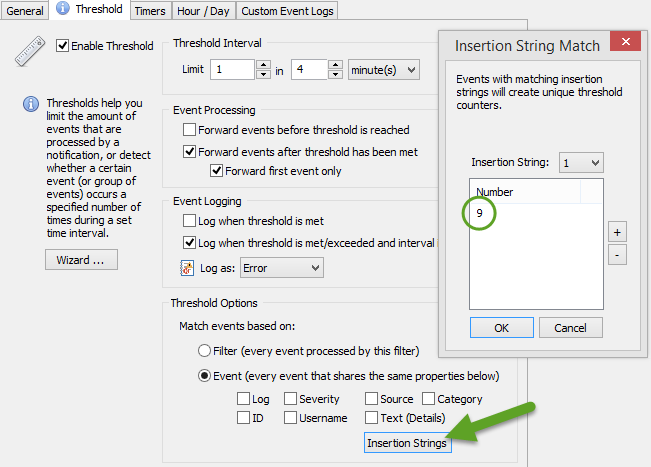
With thresholds, timers, schedules, insertion strings, EventSentry already offers a sophisticated engine for monitoring events in real time. New in this release is the ability to setup filter chaining. This makes it possible to trigger actions only when 2 or more events occur, and you can even link events together using insertion strings. Chaining is enabled on the package level, and every filter in a “chaining” package is automatically part of the filter chaining rules.
Event Annotation
It happens frequently that we get alerts that require us to do additional research based on the information provided in the alert. For example, we may get an alert about an IP address for which we then need to do a reverse lookup or find the geoip location. Audit Success & Failure events from the security event log are another example, and often contain error codes and numbers which are not explained.
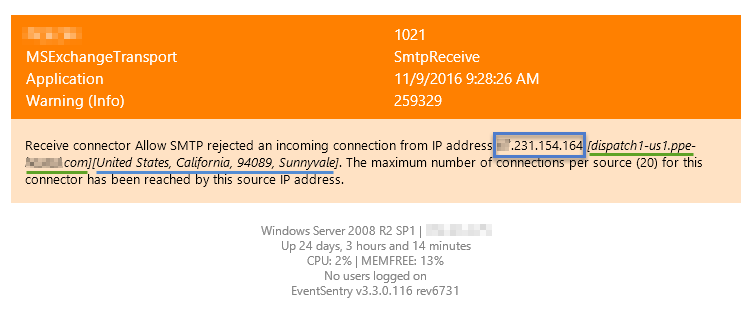
We set out to improve upon this, and starting with v3.3 EventSentry will annotate email alerts in a number of ways whenever possible:
- IP addresses will include a reverse lookup
- IP addresses will include a geoip location
- Security events will have various error codes resolved
Please note that (1) and (2) are only supported for emails sent through the collector since it requires access to a local geoip database. (1) and (2) will need to be enabled in the email action “Options”, (3) is automatically enabled for all emails.
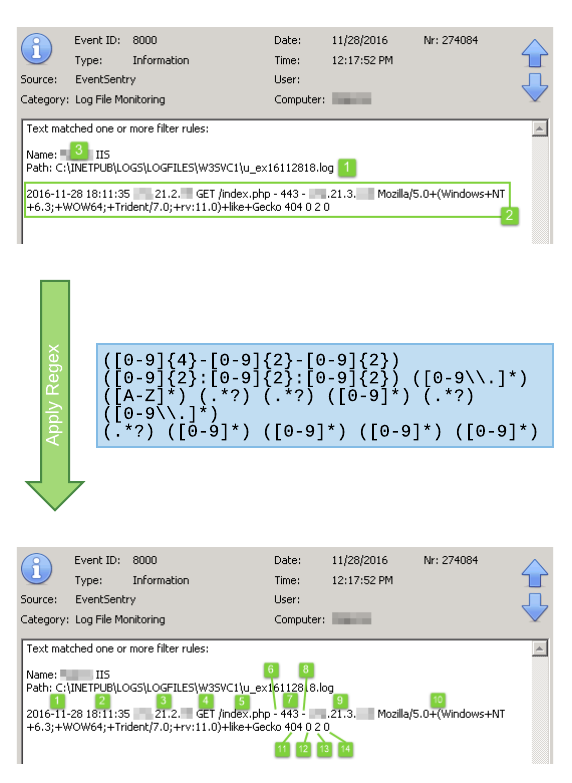
Insertion Strings & Regex
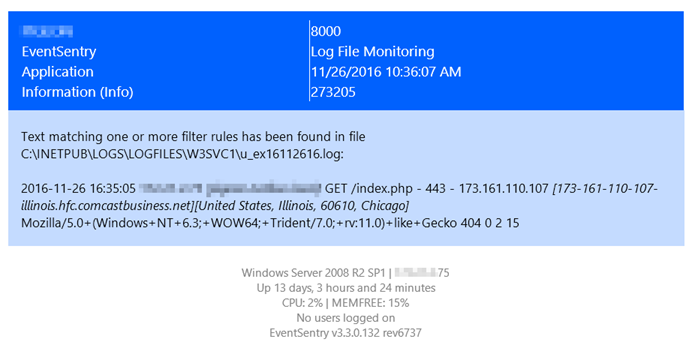
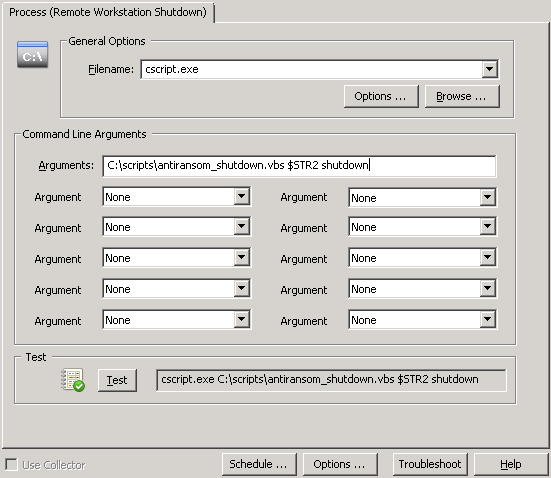
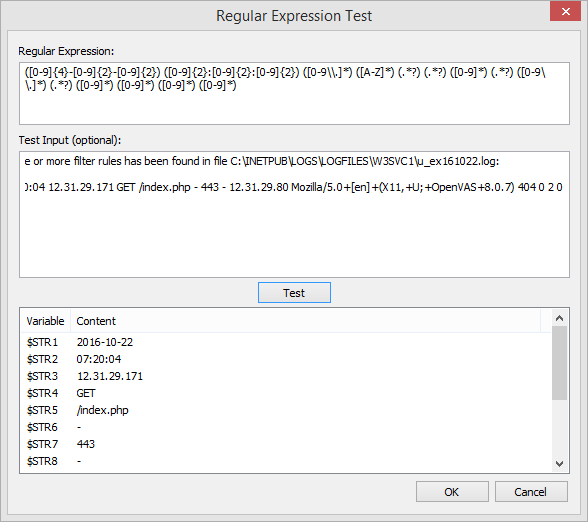
By making insertion strings from events accessible in filters and actions (e.g. through the $STR1, $STR2, … variables), it’s possible to create highly granular thresholds, customize emails, easily trigger corrective actions which utilize content from events and more. Based on our own requirements we took this capability a step further however, and you can now apply regex filters to events to define your own insertion strings. This is particularly useful for alerts which don’t use insertion strings or for events which contain log data. For those types of events, you can now parse parts of log strings and assign them to insertion strings. The previous blog article, Detecting Web Server Scan in Real-Time, shows a practical example of how to apply this new feature. It does require you to be a bit familiar with Regular Expressions, but the management console includes a handy dialog where you can test your regular expressions, shown below.
Performance
Faster is better! We’ve improved performance in a number of areas:
- The database insert performance of the Syslog daemon has been improved for Microsoft SQL Server databases
- The delimited log file feature now includes an additional index to increase database insert performance
- The heartbeat agent now relies less on RPC-based agent status monitoring and can instead obtain the status of a remote agent either directly from the collector or the database, resulting in less network traffic and faster heartbeat monitoring cycles.
With new features & improvements in a variety of areas, this release should contain improvements for everyone. Remember that you can also submit feature requests here.